

Data has become more important resource in the whole world and it is increasing day by day. There is always a relationship between one piece of data to another piece and it is amazing once we identify the pattern among those data entities. In the whole world, data is continuing according to a pattern with a connection of what happened in the past and there is always a way to predict the results of future. Many hidden and potentially useful patterns and relationships are identified using data mining techniques.
Widely used data mining methods are,
(I) pattern extraction/ identification
(II) data clustering
(III) classification/ categorization
This article will be focused on Classification and it’ s techniques with real-world application usage.
Classification is well established, supervised data mining technique where the response variable is qualitative (or categorical) and it takes one of discrete set of possible values. Classification model is created using training data and then it will be used to classify new instances. Training data set contains data which have been previously categorized and based on that the algorithms finds the category that new data points belong to. Classification problems occurs very frequently and following is a good example where we need to use classification. A bank wants to analyze the data in order to know which customers are safe and which are risky to accept the loan application.
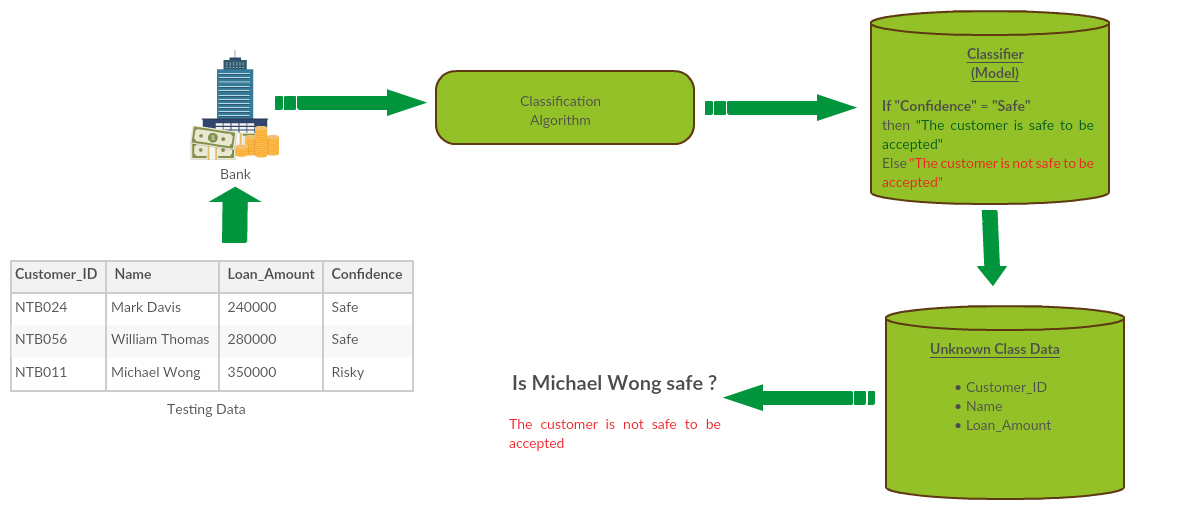 Classification is major technique in data mining and it is used widely in various fields. There are several ways which can be used to achieve classification such as decision tree induction, Bayesian network s, K-nearest neighbor classifier etc.
Classification is major technique in data mining and it is used widely in various fields. There are several ways which can be used to achieve classification such as decision tree induction, Bayesian network s, K-nearest neighbor classifier etc.
Classification classify all items in a set of data into one predefined set of classes or groups. Also, it assigns items in a collection to target categories or cases. The main goal of classification is to predict target classes accurately.
Building classifier or model have few steps. the first step is to understand the data and relationships among data. then the classification algorithms such as decision tree induction, Bayesian network s, K-nearest neighbor classifier will build the classifier. This classifier is made by database tuples and associated labels of the table. In classification each topple that constitutes the training set is referred as a category or a class. Then the classification will be used to estimate the accuracy of classification.
Many researches have been carried out for data mining using classification techniques. Widely used techniques in classification are Logistic regression, decision trees, naive based, neural networks, K nearest neighbors etc. This review will be mainly focused on Logistic regression and Linear discriminant analysis with real world classification applications and the research experiments which have been done with LR, LDA and other classification techniques like neural networks, decision trees and etc.